I obtained my bachelor’s and master’s in psychology and then completed a PhD in Epidemiology at McGill University. My journey from the quantitative social sciences to the health data science field has helped me gain a host of expertise related to study design, such as clinical trials, statistical modelling techniques drawn from causal inference and econometrics.

Erika Braithwaite

March 18, 2020

March 4, 2020
Scientific Entrepreneurship – Women in STEM
Learn more about scientific discovery, entrepreneurship, and how you can bring your research to the market
Read More
November 14, 2019
Center of Social and Culture Data Science Expo
Come join us at McGill’s CSCDS Expo on January 20, 2020!
Read More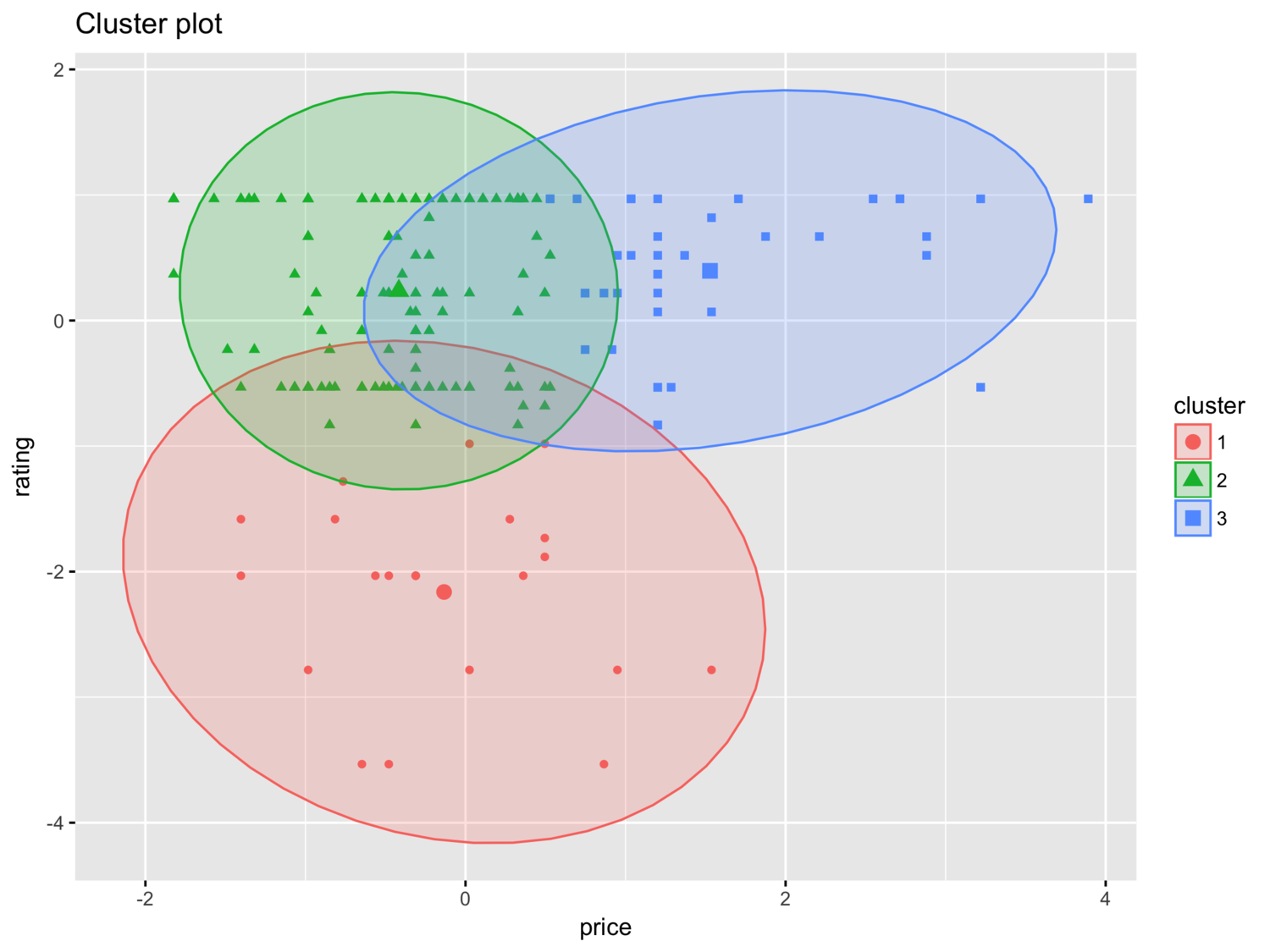
July 19, 2018
Clustering makeup data with K-means
Continuing my makeup data exploration using k-means clustering
Read More
May 3, 2018
Visualizing makeup data using R
How I used R to visualize data from a makeup API that I randomly stumbled across
Read More
November 14, 2017
Social epidemiology and open source data
My favourite open-source data sets relating to social issues surrounding health
Read More